
哪些本地模型与 Cline 真正兼容?AMD 对它们进行了全部测试
AMD 发布了关于使用 Cline、LM Studio 和 VS Code 进行本地“氛围编码”(vibe coding)的 综合指南。在测试了 20 多个模型后,他们发现只有少数模型能可靠地用于编码任务。大多数较小的模型会产生损坏的输出或完全失败。
尽管 AMD 在 Windows 硬件上进行了测试,但他们的发现具有普遍性。无论您使用 Windows、Mac 还是 Linux,RAM 要求和模型限制都是相同的。以下是哪些模型有效、您需要多少 RAM,以及如何在您的平台上配置一切。
如果您一直想知道自己的机器是否能够运行本地模型,这里有明确的答案。
了解您的硬件
首先,让我们检查一下您的工作环境。LM Studio 通过视觉指示器,让您可以轻松查看硬件可以处理哪些模型。
检查您的 RAM
- Mac:苹果菜单 → 关于本机 → 内存
- Windows:任务管理器 → 性能 → 内存
- Linux:在终端中输入
free -h
RAM 和 VRAM 之间的区别很重要。系统 RAM 决定了您可以加载哪些模型,而 VRAM(在专用显卡上)会影响推理速度。对于具有集成显卡的 AMD 系统,您需要配置可变显存 (VGM) 来为 GPU 任务分配系统 RAM。
GGUF vs MLX:选择您的格式
唯一的平台特定选择是您的模型格式
GGUF(GPT-Generated Unified Format)
- 适用于 Windows、Linux 和 Mac
- 广泛的量化选项(2 位到 16 位)
- 跨工具具有更广泛的兼容性
- 适用于 Windows/Linux 或跨平台需求
MLX(Apple 的机器学习框架)
- 仅限 Mac,针对 Apple Silicon 优化
- 利用 Metal 和 AMX 加速
- 在 M1/M2/M3 芯片上推理速度更快
- 如果您只使用 Mac,请选择此选项
量化:平衡质量和性能
量化通过降低模型精度来节省内存。为了理解您所做的权衡,请考虑像 Claude Sonnet 4.5 或 GPT-5 这样的云 API 在庞大的服务器基础设施上以全精度(16 位甚至 32 位浮点数)运行。当您在本地运行时,量化使这些模型能够适应消费级硬件。
数字的含义
- 4 位:将模型大小减少约 75%。就像压缩的 JPEG 一样;您会丢失一些细节,但它完全可用。对于编码任务,大多数用户不会注意到质量差异。
- 8 位:将模型大小减少约 50%。比 4 位质量更好。响应更细致入微,边缘情况错误更少。压缩程度较低的高质量 JPEG。
- 16 位:全精度,与云 API 匹配。需要 4 倍于 4 位的内存,但提供最大质量。未压缩的原始文件。
AMD 的测试证实,4 位量化为编码任务提供了生产级质量。本地 4 位与全精度云模型之间的差异通常不如模型架构本身之间的差异明显。一个 4 位 Qwen3 Coder 将优于许多全精度的小模型。
Mac 36GB RAM x qwen/qwen3-coder-30b (4 位)
内存需求示例
- Qwen3 Coder 30B 4 位:约 17GB 下载
- Qwen3 Coder 30B 8 位:约 32GB 下载
- Qwen3 Coder 30B 16 位:约 60GB 下载
在检查了您的硬件并了解了量化之后,以下是您可以运行的具体内容。
按 RAM 等级划分的模型指南
快速参考
| RAM | 最佳模型 | 下载大小 | 上下文长度 | 紧凑提示词 | 您将获得 |
|---|---|---|---|---|---|
| 32GB | Qwen3 Coder 30B (4 位) | 17GB | 32K | 开启 | 入门级本地编码 |
| 64GB | Qwen3 Coder 30B (8 位) | 32GB | 128K | 关闭 | 完整的 Cline 功能 |
| 128GB+ | GLM-4.5-Air (4 位) | 60GB | 128K+ | 关闭 | 云级别性能 |
32GB RAM:最低可行等级
主要模型: Qwen3 Coder 30B A3B (4 位) – 尽管有 30B 参数,但在推理过程中只有 3.3B 处于活动状态。Windows/Linux 选择 GGUF,Mac 选择 MLX。
荣誉提名: mistralai/magistral-small-2509, mistralai/devstral-small-2507
AMD 的测试证实这是入门点。您需要启用紧凑提示词(Compact Prompts),这会减少一些 Cline 功能,但保留核心编码能力。许多用户成功地将上下文长度推到 AMD 推荐的 32K 之外,一直到 256k。
64GB RAM:最佳选择
主要模型: Qwen3 Coder 30B A3B (8 位) – 相同的模型,更好的质量
这解锁了完整的 Cline 体验。紧凑提示词关闭,模型响应明显更细致入微。
128GB+ RAM:理想境界
主要模型: GLM-4.5-Air (4 位) – AMD 的首选,具有 106B 参数(通过 MoE 激活 12B)
荣誉提名: Nousresearch/hermes-70B, openAI/gpt-0ss-120b
最先进的本地性能。您可以同时运行多个模型,并获得真正具有云竞争力的结果。
设置您的本地堆栈
一旦您根据 RAM 选择了模型,设置就很简单了。
LM Studio 配置
- 下载正确的模型:使用 LM Studio 的搜索功能找到您选择的模型。界面会用绿色对勾显示兼容性。
- 关键设置:
- 上下文长度:与您的 RAM 等级匹配
- Flash Attention:对于 AMD 硬件和高上下文至关重要
- KV Cache Quantization:保持禁用以获得一致的性能
- 服务器设置:
- 导航到开发者选项卡
- 加载您的模型
- 启动服务器(默认: http://127.0.0.1:1234)
Cline 配置
- 提供商:选择 LM Studio
- 模型:匹配您加载的模型(例如,qwen/qwen3-coder-30b)
- 上下文窗口:匹配 LM Studio 的设置
- 紧凑提示词:根据您的 RAM 等级设置
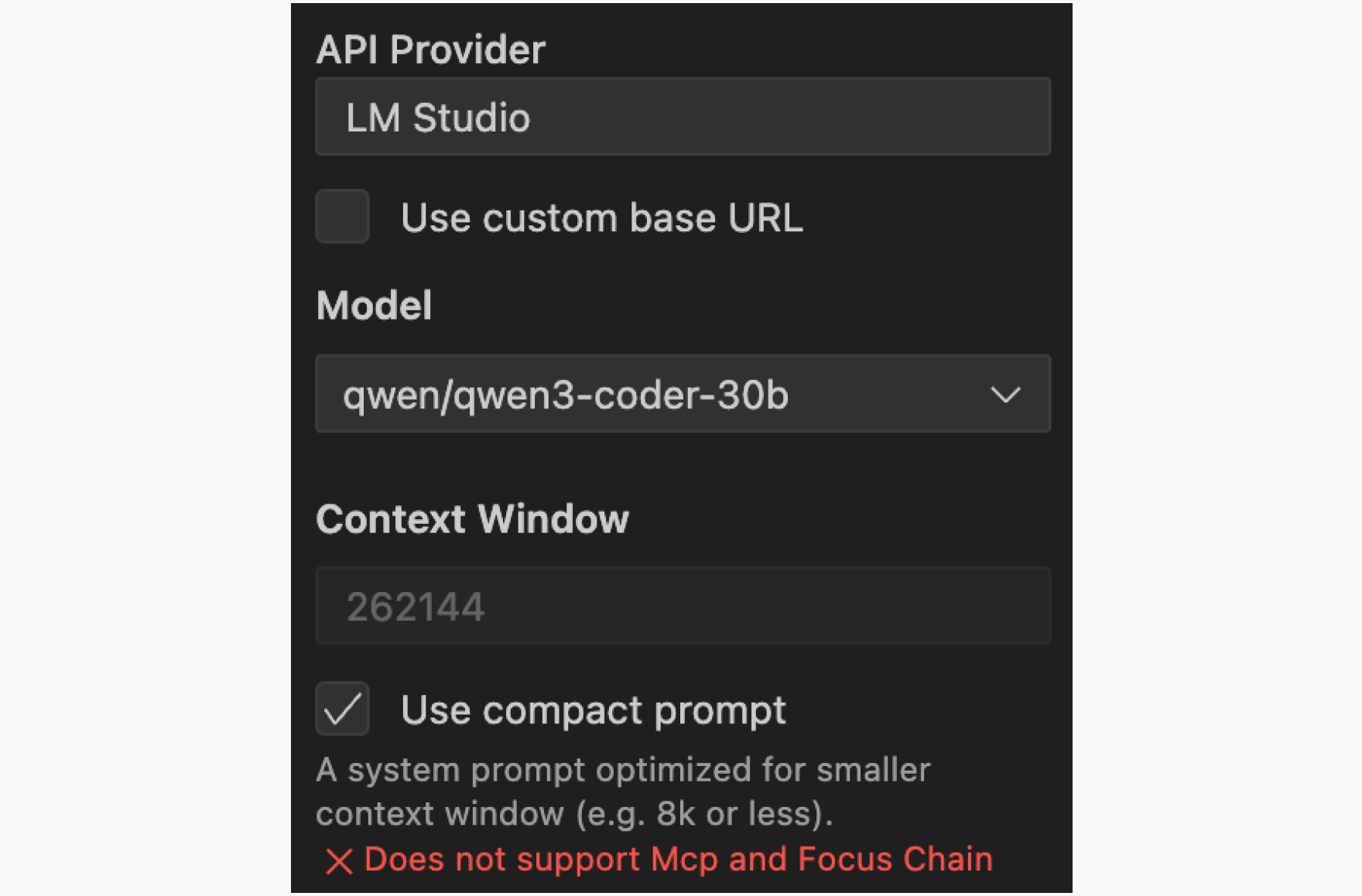
紧凑提示词设置将系统提示词减少 90%,这对于性能至关重要。通过将 Cline 的提示词减少到原始大小的约 10%,您显着提高了响应速度。通常会减慢每次交互的提示词权重被移除,使模型感觉更灵敏、响应更快。您牺牲了一些高级功能(MCP 工具、焦点链)来换取这种性能提升,但核心编码能力仍然完全保持不变。
平台特定配置
Windows 用户(AMD 硬件)
AMD Ryzen AI 平台
- 通过 AMD Software: Adrenalin Edition 配置可变显存 (VGM)
- 右键单击桌面 → AMD Software → 性能 → 调整
- 根据 AMD 的矩阵设置专用显存
AMD Radeon 显卡
- 安装 AMD Software: Adrenalin Edition 25.8.1+ 以支持 llama.cpp
- Radeon PRO 用户需要 PRO Edition 25.Q3 或更高版本
- 专用显卡无需配置 VGM
NVIDIA 用户
- 确保安装了 CUDA 驱动程序以进行 GPU 加速
- 使用 GGUF 格式以获得最佳兼容性
Mac 用户
- 使用 MLX 格式进行 Apple Silicon 优化 (M1/M2/M3)
- 无需额外的驱动程序
- Metal 加速开箱即用
- 对于 Intel Mac,使用 GGUF 格式
Linux 用户
- 使用 GGUF 格式
- 安装 CUDA (NVIDIA) 或 ROCm (AMD) 驱动程序以进行 GPU 加速
- 纯 CPU 推理无需额外设置即可工作
那些不工作的模型
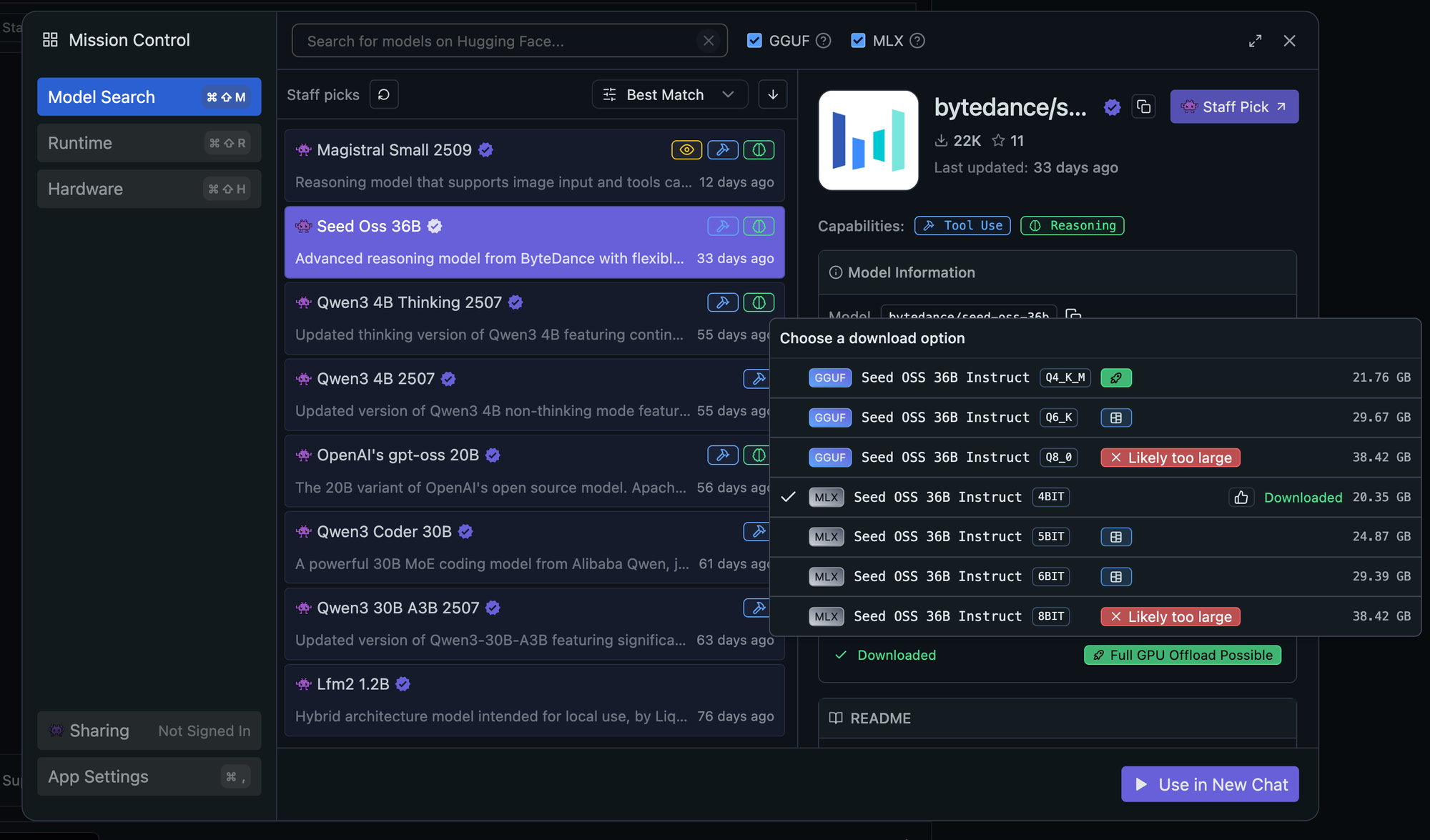
AMD 的测试显示,小于 Qwen3 Coder 30B 的模型与 Cline 一起使用时会持续失败,产生损坏的输出或无法正确执行命令。这包括一些流行的较小模型,它们在聊天方面表现良好,但缺乏自主编码任务的能力。在我们的测试中,这些模型包括 gpt-oss-20b、bytedance/seed-oss-36b 和 deepseek/deepseek-r1-0528-qwen3-8b。
这不是模型本身的限制,而是模型能力与 Cline 对工具使用、代码理解和自主操作的要求不匹配。
入门
从 https://lm-studio.cn 下载 LM Studio 并为 VS Code 安装 Cline。根据您的 RAM 等级搜索您的模型,配置我们介绍的设置,并将 Cline 指向您的本地端点。
您的硬件决定了您的选择,但即使是入门级的 32GB 机器也可以运行真正有用的本地编码代理。


