
Cline + LM Studio:使用 Qwen3 Coder 30B 的本地编码堆栈
您现在可以完全离线运行 Cline。没有 API 费用,没有数据离开您的机器,不依赖互联网。只有您、您的笔记本电脑和一个可以分析存储库、编写代码和执行终端命令的 AI 编码代理——所有这些都可以在您身处大洋中的船上完成。
AMD 刚刚发布了一份关于使用 Cline + LM Studio 进行本地编码的指南。请在此处查看。
该堆栈很简单:LM Studio 提供运行时,Qwen3 Coder 30B 提供智能,而 Cline 协调工作。它们共同创建了一个既强大又私密的本地编码环境。
一个转折点
本地模型已经跨越了一个门槛。Qwen3 Coder 30B,特别是在 Apple Silicon 上经过优化的 MLX 格式,提供了对实际编码任务真正有用的性能。这不再是玩具或概念验证——它已经为编码代理做好了准备,并且可以完全在您的硬件上运行。
该模型带来了 256k 的原生上下文、强大的工具使用能力和存储库级别的理解。结合 Cline 的紧凑提示系统(专为本地模型设计,长度仅为 10%),您可以获得一个可以处理大量编码任务而无需接触云的代理。
您需要什么
设置很简单
- LM Studio 用于模型托管和推理
- 用于 VS Code 的 Cline
- 将 Qwen3 Coder 30B 作为您的模型
对于使用 Apple Silicon 的 Mac 用户,MLX 构建已针对您的硬件进行了优化。Windows 用户(以及其他所有人)使用 GGUF 构建可获得出色的性能。LM Studio 会自动为您平台建议正确的格式。
设置 LM Studio
首先下载模型。在 LM Studio 中,搜索 "qwen3-coder-30b" 并选择 Qwen3 Coder 30B A3B Instruct。该平台将推荐 Mac 上的 MLX 和 Windows 上的 GGUF——两者都运行良好。
根据您的硬件选择合适的量化。对于我的 36B RAM Mac 来说,这意味着 4 位量化模型
对于本地模型,量化 是将模型权重(数字)的精度降低到一组较小的整数或较低精度浮点值的过程,这使得模型文件大小和内存更小,运行速度更快,从而更适合在消费级硬件上使用。虽然这会在精度和性能之间产生权衡,但复杂的S技术旨在最大限度地减少准确性损失,从而允许用户在个人计算机上运行强大的 AI 模型,例如大型语言模型(LLM)。
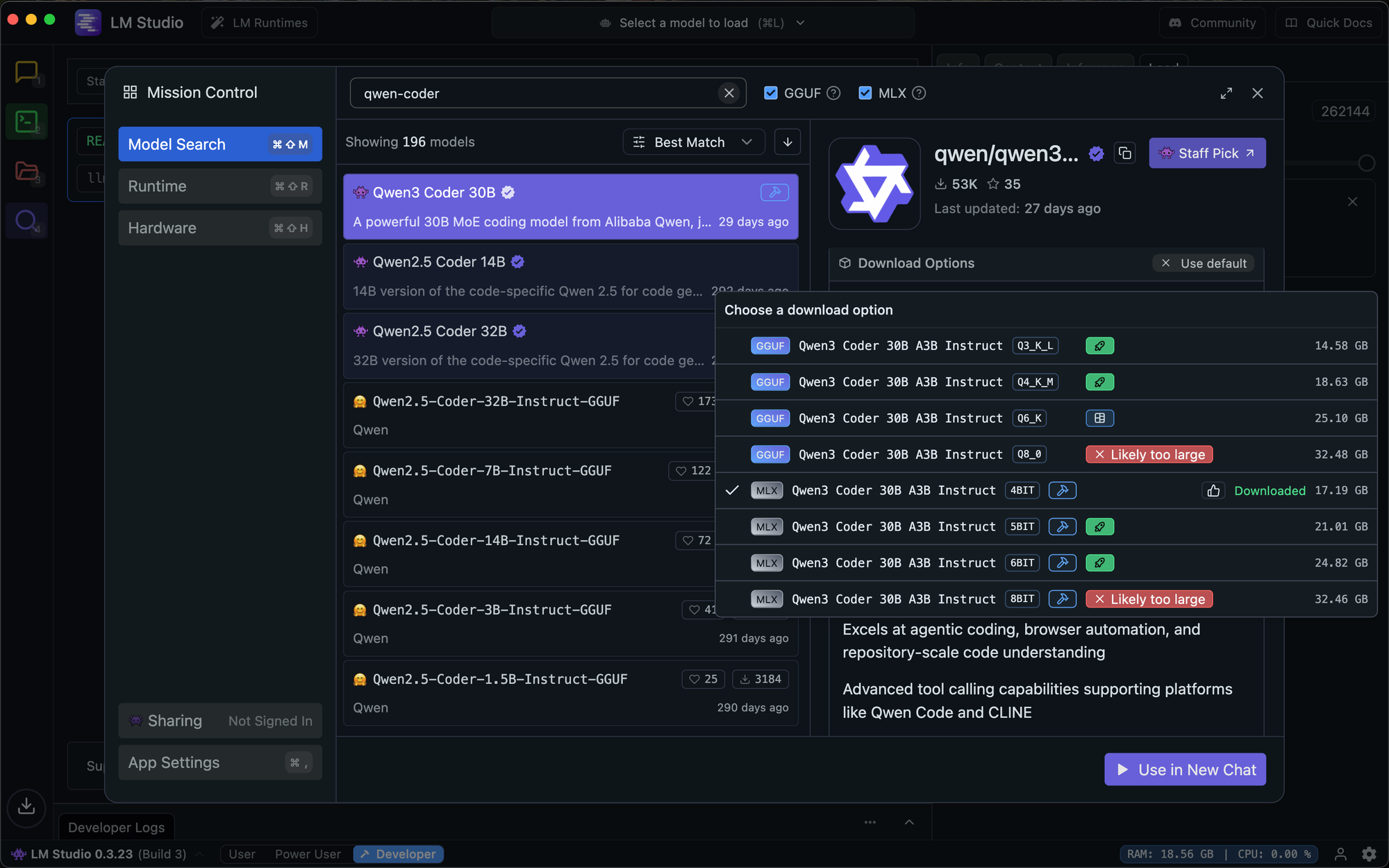
下载完成后,转到“开发人员”选项卡。选择您的模型,加载它,然后将服务器切换为“正在运行”。默认端点是 http://127.0.0.1:1234。
配置这些关键设置
- 上下文长度:设置为 262,144(模型的最大值)
- KV 缓存量化:保持未选中
KV 缓存设置非常重要。虽然它对于某些过程可能是一种优化,但它会在任务之间保留上下文并产生不可预测的行为。保持关闭以获得一致的性能。
配置 Cline
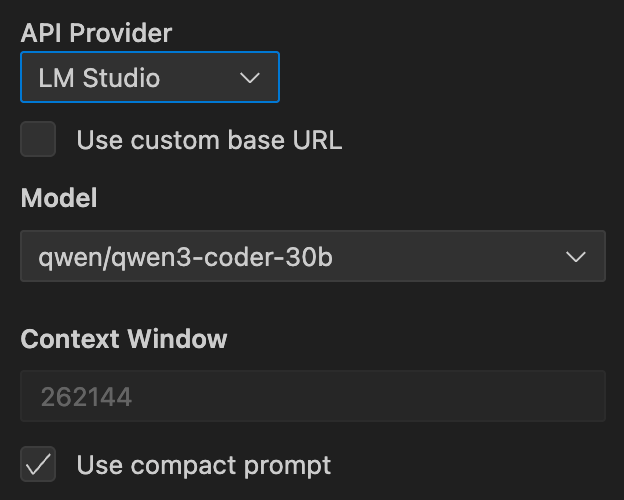
在 Cline 的设置中,选择 LM Studio 作为您的提供商,选择 qwen/qwen3-coder-30b 作为您的模型。如果您使用的是默认本地端点,请不要设置自定义基础 URL。
将您的上下文窗口与 LM Studio 的设置匹配:262,144 个令牌。这为您处理大型存储库和复杂任务提供了最大的工作空间。
启用“使用紧凑提示”。这对于本地模型至关重要。紧凑提示的大小约为 Cline 完整系统提示的 10%,使其对于本地推理效率更高。缺点是您无法使用 MCP 工具、焦点链和 MTP 功能,但您获得了针对本地性能优化的简化体验。
性能特点
Qwen3 Coder 30B 在现代笔记本电脑上表现良好,尤其是 Apple Silicon 机器。MLX 优化使得 30B 参数模型的推理速度出奇地快。
首次加载模型时会有一段预热时间。这很正常,每个会话只会发生一次。随着时间的推移,大型上下文摄取会变慢——这是长上下文推理固有的。如果您正在处理大型存储库,请考虑分阶段进行工作或减少上下文窗口。
4 位量化实现了出色的平衡。如果您有内存空间并希望获得稍好的质量,可以使用 5 位或 6 位选项。对于大多数用户而言,4 位提供了最佳体验。
离线优势
此设置可实现真正的离线编码。您的笔记本电脑成为一个自给自足的开发环境,Cline 可以在其中分析代码库、提出改进建议、编写测试并执行命令——所有这些都不依赖于网络。
隐私影响非常重要。您的代码永远不会离开您的机器。对于敏感项目或气隙环境,此本地堆栈提供了以前根本无法实现的功能。
成本影响同样引人注目。没有 API 令牌,没有使用计量器,没有意外账单。下载模型后,一切都在本地运行,无需额外费用。
何时使用本地堆栈
本地模型擅长
- 离线开发会话,其中互联网不可靠或不可用
- 隐私敏感项目,其中代码不能离开您的环境
- 注重成本的开发,其中 API 使用成本高昂
- 学习和实验,您希望获得无限使用
云模型仍然具有优势
- 非常大的存储库,超出本地上下文限制
- 数小时的重构会话,受益于最大的可用上下文窗口
- 团队,需要跨不同硬件保持一致的性能
故障排除
如果 Cline 无法连接到 LM Studio,请验证服务器是否正在运行并且已加载模型。“开发人员”选项卡应显示“服务器:正在运行”和您选择的模型。
如果模型似乎没有响应,请确认 Cline 中启用了“使用紧凑提示”并且 LM Studio 中禁用了“KV 缓存量化”。这些设置对于正常运行至关重要。
如果性能在长时间会话期间下降,请尝试将上下文窗口减少一半或在 LM Studio 中重新加载模型。非常长的上下文可能会使本地推理紧张。
入门
从 https://lm-studio.cn 下载 LM Studio 并安装 Cline for VS Code。搜索 Qwen3 Coder 30B A3B Instruct,下载 4 位版本,启动服务器,并配置 Cline 以使用启用了紧凑提示的本地端点。
您的离线编码代理已准备就绪。
准备好无限制地编码了吗? 下载 Cline 并体验本地优先的 AI 开发。在我们的 Reddit 和 Discord 社区分享您的离线编码成果。


