
GLM-4.6 vs Sonnet 4.5 — 开源差异编辑的融合 | Cline 报告
本周标志着 AI 编程的一个拐点。Anthropic 的 Claude Sonnet 4.5 于周一发布;zAI 的 GLM-4.6 紧随其后于周二发布。这两款模型都受到了好评,但更深层次的故事在于 Cline 的真实遥测数据:在我们追踪的最困难的编码任务模式——差异编辑中,高级模型和开源模型之间的性能差距已缩小至基点(basis points),而非百分点。
开源模型的融合
人工智能分析编码指数(Artificial Analysis Coding Index)已经追踪这一趋势数月。开源模型在智能方面正在追赶闭源模型,但在编码能力方面追赶得更快。这不是猜测;它可以通过基准测试、实际使用情况以及我们从数百万次 Cline 操作中获得的数据来衡量。
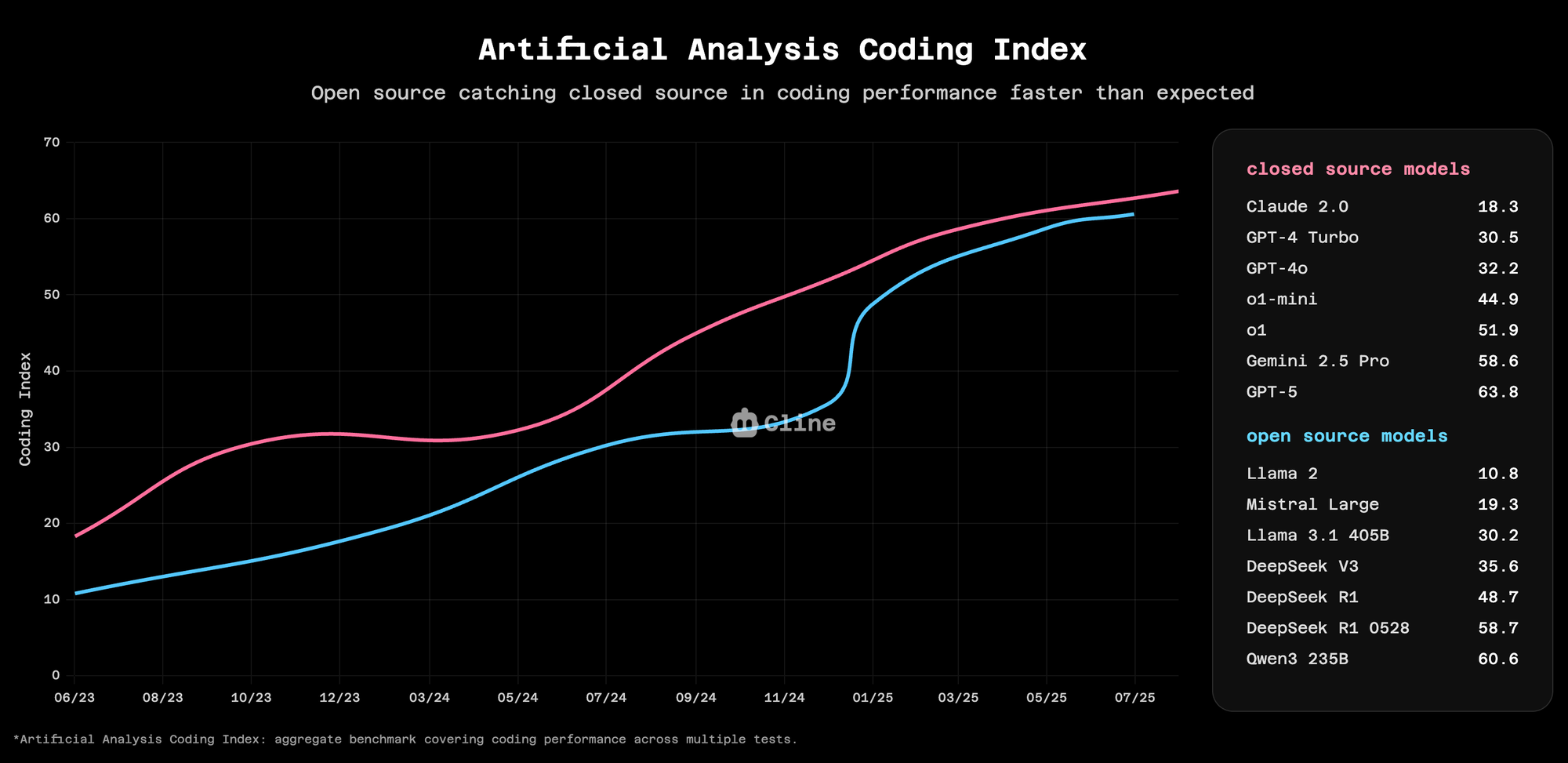
为什么 Cline 的数据很重要
差异编辑是对 AI 编码模型最困难的测试。它们需要理解上下文、保持一致性,并对现有代码进行精确的局部修改。与从头开始生成新代码不同,差异编辑测试的是模型是否真正理解它正在修改的内容。
我们分析了过去四个月 Cline 用户数百万次的差异编辑操作。结果清晰地说明了本周发布的模型情况。
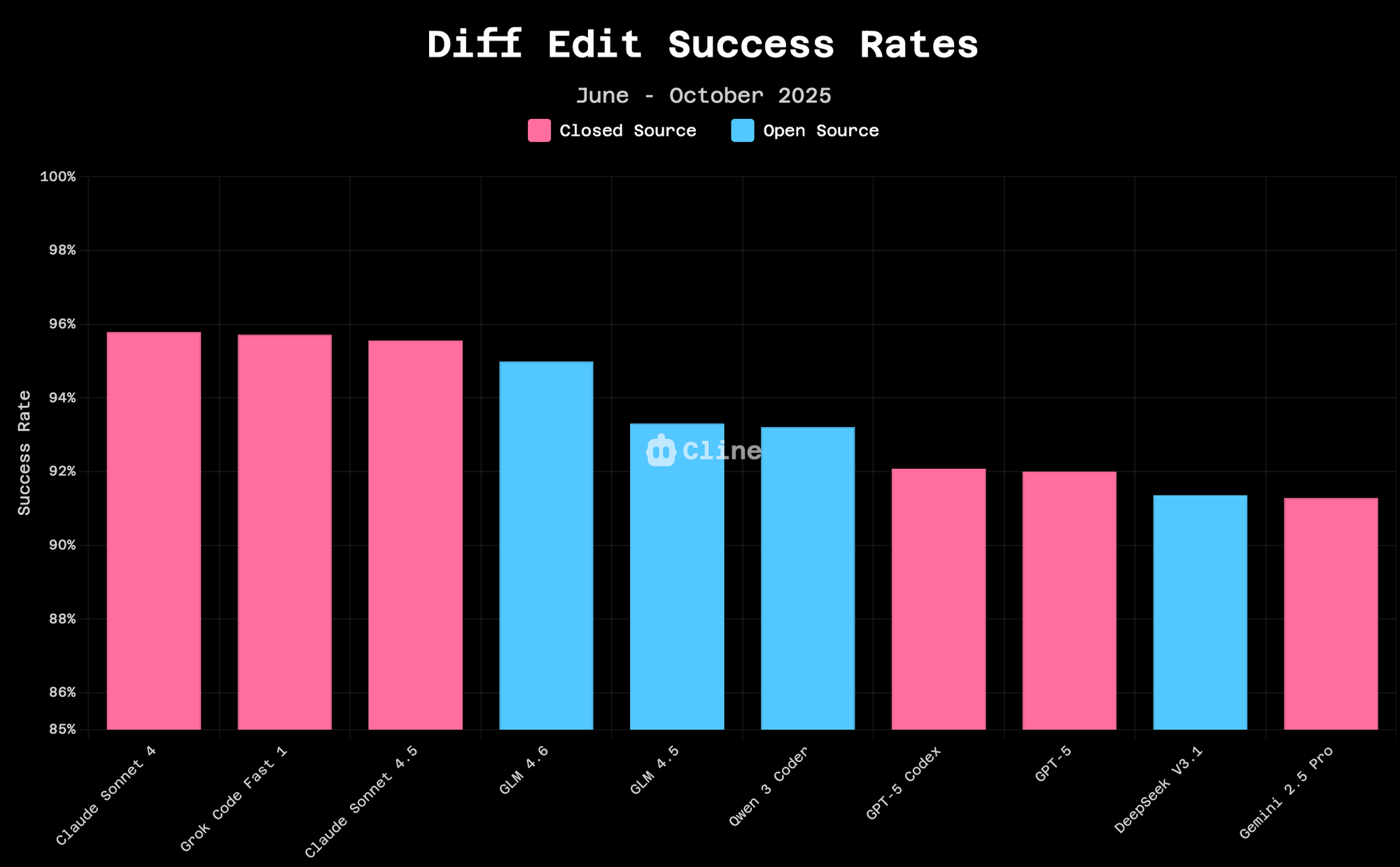
性能集群现象非常引人注目。Claude 4 Sonnet 在差异编辑上的成功率为 95.8%。Claude 4.5 Sonnet 略微提高至 96.2%。GLM-4.6 的成功率为 94.9%。这些差异是可衡量的,但微乎其微;我们谈论的是基点差距,而不是百分点差距。
作为参考,仅仅三个月前,高级模型和开源模型在这些任务上的差距还在 5-10 个百分点。这种融合正在加速。
Cline 内部的社区脉搏
Cline 的 Discord 上的开发者们将 Sonnet 4.5 描述为“所需修正减少了一半”,指令遵循更严格,初稿更简洁。GLM-4.6 则因其“以极低成本接近 Sonnet”而引起兴奋,在实际项目中经常与 Sonnet 4.5 并驾齐驱。这种热情不仅仅关乎原始性能,更关乎可及性。
经济因素不容忽视
这些模型之间的成本差异是巨大的
- Claude Sonnet 4.5:每百万输入 token 3 美元,每百万输出 token 15 美元
- GLM-4.6:每百万输入 token 0.50 美元,每百万输出 token 1.75 美元
- Qwen3 Coder:每百万输入 token 0.22 美元,每百万输出 token 0.95 美元
zAI 的 GLM 编码计划更进一步,以每月仅 6 美元的价格提供 GLM-4.6 访问权限,每 5 小时周期提供 120 个提示。对于许多开发者来说,这使得 AI 编码从奢侈品转变为实用工具。
这种融合意味着什么
趋势线非常清楚。开源模型的改进速度持续快于闭源模型。虽然这一趋势并不意味着开源模型一定会取代闭源前沿,但每一次发布都会进一步缩小差距。GLM-4.6 在差异编辑上达到 95% 的成功率,在六个月前对于开源模型来说是不可想象的。
这种融合超出了云模型。本周,AMD 演示了像 Qwen3 Coder 这样的模型可以在只有 32GB RAM 的消费级硬件上有效运行。差距不仅在云端缩小,也在你的笔记本电脑上缩小。
随着模型在能力上趋同,差异化将来自生态系统、工具和专业功能。好的代码生成的基础正在商品化。接下来重要的是这些模型如何融入开发者的工作流程。
准备好尝试这些模型了吗? 下载 Cline 并体验 GLM-4.6 和 Sonnet 4.5。加入 Reddit 和 Discord 上的讨论,分享您的体验。


