
第 2 章:LLM 基准测试
基准测试的实际衡量内容
语言模型领域的基准测试与教育中的标准化测试有相似之处:它们提供了一种一致的方法来比较不同模型在特定能力上的表现。然而,就像 SAT 高分并不能保证在所有大学专业中都能成功一样,基准测试的高分也不能保证模型在您抛给它的所有任务中都表现出色。
关键在于,不同的基准测试衡量的是智能和能力的不同方面。有些侧重于纯粹的编码能力,有些侧重于特定领域的知识,还有一些则侧重于有效使用工具的能力。理解这些区别有助于您将基准测试表现与您在 Cline 中的实际需求相匹配。
编码能力基准测试
由于编码是大多数 Cline 用户的主要用例,衡量编程能力的基准测试值得特别关注。这些测试评估模型理解现有代码、生成新代码以及解决编程问题的能力。
SWE-Bench 尤为相关,因为它根据真实世界的软件工程挑战来测试模型。SWE-Bench 不是使用人工编码问题,而是收集了流行开源项目中的实际 GitHub issue。当模型在 SWE-Bench 上表现良好时,它表明该模型具备理解复杂代码库、识别错误以及实现能在实际生产环境中运行的修复方案的能力。
这种对真实世界的关注使得 SWE-Bench 的结果高度预测了当您要求 Cline 修复错误、实现功能或重构现有代码时模型的表现。该基准测试正是衡量您日常开发工作中可能遇到的任务类型。
然而,SWE-Bench 有一个重要的局限性:数据污染。一些模型可能在训练期间遇到过基准测试中使用的特定 GitHub issue,从而获得了不公平的优势。这就是 SWE-Bench Verified 存在的原因——它手动验证测试用例代表的是真正的解决问题能力,而不是记忆。
互补的编码基准测试,如 HumanEval、LiveCodeBench 和 BigCodeBench,分别测试了编程能力的不同方面。HumanEval 侧重于从自然语言描述生成函数级代码。LiveCodeBench 针对最近的编程问题进行测试,以最大限度地减少污染。BigCodeBench 评估模型在需要理解多个文件和系统的更大、更复杂编码任务中的表现。
当为高编码强度的 Cline 用法选择模型时,考察其在多个编码基准测试中的一致表现比仅依赖单一分数更可靠。
特定领域知识基准测试
许多 Cline 用例超出了纯粹的编程范畴,涉及需要深厚专业知识的专业领域。如果您正在构建医疗保健应用、金融建模系统或科学计算工具,您的模型需要的不仅仅是编码能力——它还需要领域知识。
MMLU (大规模多任务语言理解) 测试模型在 57 个不同学术科目上的表现,从基础数学到专业法律和医学。在 MMLU 生物学部分得分高的模型更有可能理解医疗保健数据处理的细微差别。在数学部分表现出色则表明在金融建模或科学计算应用方面具有更好的能力。
GPQA (研究生水平 Google-Proof 问答) 专门侧重于生物学、物理学和化学的研究生级别问题。这些问题设计得即使对于该领域的专家来说也具有挑战性,使得 GPQA 表现成为衡量深度领域理解力的有力指标。
AIME (美国数学邀请赛) 测试高级数学推理能力。对于涉及复杂算法、优化问题或数学建模的应用,AIME 表现可以预测模型处理开发任务中数学方面的能力。
关键在于将基准测试领域与您的应用领域相匹配。如果您正在构建金融软件,优先考虑在经济学和数学基准测试中表现出色的模型。对于医疗保健应用,寻找在生物学和医学评估中表现优异的模型。
工具使用和 MCP 能力
Cline 最强大的功能之一是通过 模型上下文协议 (MCP) 与外部工具和服务集成。此功能实现了从网络爬取和浏览器自动化到实时文档和扩展内存系统的所有功能。
然而,并非所有模型都擅长工具使用。有些模型难以处理工具调用所需的精确格式,有些模型在何时使用工具方面做出不一致的决策,还有些模型无法有效地将多个工具调用串联起来。
衡量工具使用能力的基准测试仍在不断发展中,但它们通常测试模型是否能正确格式化工具调用、为给定任务选择合适的工具,以及在多次交互中保持一致性。这些基准测试通常涉及诸如“使用网络搜索工具查找有关 X 的信息,然后使用计算器工具根据该信息执行计算 Y”之类的场景。
对于严重依赖 MCP 集成的 Cline 设置,工具使用基准测试表现成为一个关键的选择标准。一个擅长纯粹编码但难以处理工具调用的模型,当您需要它与外部服务交互时,会带来令人沮丧的体验。
基准测试的局限性
虽然基准测试提供了宝贵的指导,但它们只讲述了故事的一部分。基准测试表现代表了受控条件下的能力,但您的实际 Cline 用法涉及独特的代码库、特定的需求和特定的工作流程,这些都不是任何基准测试能完全捕捉到的。

考虑两个 SWE-Bench 分数相似的模型。一个可能擅长 Python web 开发,但在嵌入式系统编程方面表现不佳。另一个可能很好地处理系统编程,但生成的 web 应用代码冗长且难以维护。仅凭基准测试分数无法揭示这些差异。
这就是为什么在您自己的环境中进行实验仍然至关重要。基准测试可以帮助您将选择范围缩小到具有相关能力的模型,但只有亲身实践才能揭示哪个模型最适合您的特定用例。
实用的评估策略
最有效的方法是将基准分析与实际实验相结合。首先确定您的主要 Cline 用例:您主要是在修复错误和实现功能吗?在专业领域工作吗?严重依赖 MCP 集成吗?
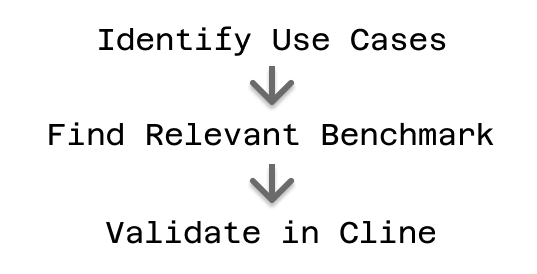
一旦您了解了用例,就寻找在相关基准测试中表现良好的模型。对于以编码为中心的工作,优先考虑 SWE-Bench、HumanEval 和相关的编程基准测试。对于特定领域应用,检查 MMLU 在相关学科领域的表现。对于 MCP 密集型工作流程,寻找工具使用基准测试结果。
在根据基准测试表现确定有希望的候选模型后,利用 Cline 的模型不可知设计在您的实际环境中测试它们。使用不同的模型尝试相同的复杂任务,并观察结果的质量,以及每个模型采取的方法、其输出的一致性以及它与您现有工作流程的集成程度。
这种结合了基准测试指导的选择和实际测试的方法,帮助您找到不仅在标准化测试中得分高,而且在您的特定开发挑战中也表现出色的模型。
理解的演变
随着您在 Cline 环境中积累使用不同模型的经验,您将培养出超越任何基准测试所能衡量的直觉。您将了解哪些模型能很好地处理您的编码风格,哪些模型能顺利地与您偏好的框架集成,以及哪些模型能为您的工作流程提供适当的能力和成本平衡。
这种经验知识补充了基准测试数据,形成了对模型能力的全面理解。基准测试提供了评估的初始框架,而您的亲身经验则填补了对您的特定用例最重要细节。
准备好将基准测试见解应用于您的模型选择过程了吗?首先确定哪些基准测试与您的主要 Cline 用例一致,然后开始在您的实际开发环境中试验表现最佳的模型。
有关详细的基准测试比较和模型选择指南,请访问我们的文档。在 Reddit 和 Discord 上分享您的基准测试经验,并向其他开发人员的模型评估学习。


