
Cline 框架内部:优化上下文、保持叙事完整性和实现更智能 AI
有效的上下文管理是与 AI 编码助手进行高效协作的基石。随着与 Cline 的对话不断演变并变得越来越复杂,如何处理上下文窗口空间有限这一长期存在的问题变得越来越重要——同时还要确保在 extended conversations 期间保持叙事完整性。
为什么要关注 token 效率?因为我们正在了解到,更智能的上下文管理是性能的基础。修剪不必要的上下文可以降低成本,是的,但更重要的是,它能增强准确编码所需的叙事完整性。
我们新的通用框架
我们构建了一个新框架,用于改进我们如何处理保留在上下文窗口中的内容,以共同最小化 token 使用并优化 Cline 的功能。为此,我们首先构建了关键功能,以解决我们看到用户提到的关键问题——截断对话历史后保持叙事完整性,以及处理填充上下文窗口的大量冗余文件读取。
让我们更详细地了解一下我们如何管理文件读取。当用户在同一代码库上长时间工作时,Cline 会根据其工具调用和用户输入多次加载同一个文件。这包括对 read_file、replace_in_file、write_to_file 和 @ mentions 的调用。这对于让 Cline 访问每个文件的最新版本非常重要,因为用户会继续编辑它、询问有关它的问题、使用它等等。然而,这也意味着上下文窗口最终会堆满同一文件的多个旧版本。
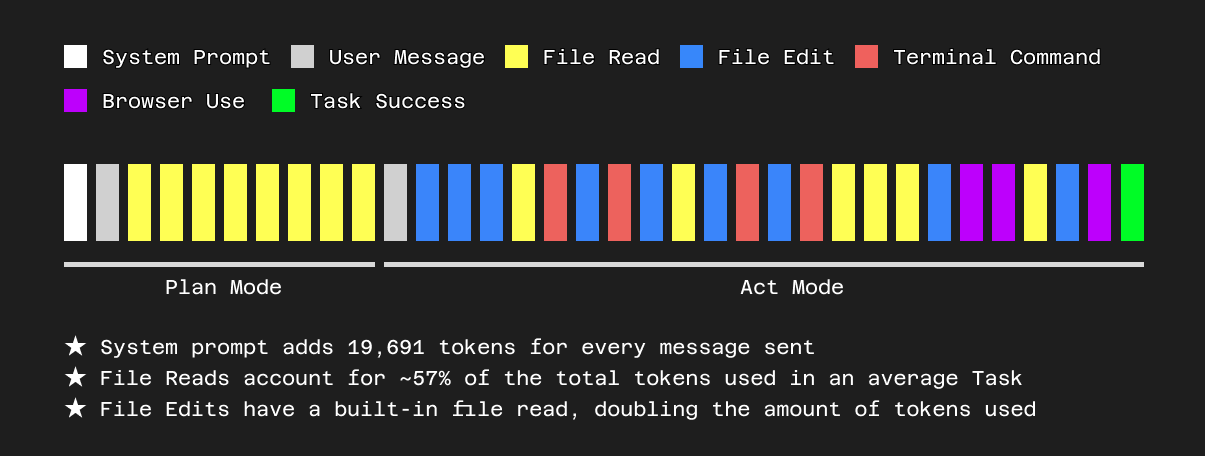
这不仅浪费了上下文窗口中宝贵的空间,而且从我们在内部评估中看到的情况来看,可能会导致某些 LLM 模型更难识别用于编辑的正确文件块,最终导致使用 replace_in_file 等工具时错误率更高。作为我们新上下文管理框架的第一步,我们已经开始删除这些过时的旧文件读取,只在上下文中保留文件的最新版本,同时保留对话的整体叙事完整性。我们采用了一种非常保守的方法来确定在删除不必要的文件读取后是否仍需要截断旧消息,因为我们还希望最大限度地利用提示缓存来降低用户成本。
这种谨慎的平衡延伸到提示缓存。虽然删除过时的文件读取是明显的优势,但过度截断旧消息可能会破坏缓存,从而可能增加后续轮次的成本。我们目前的方法优先考虑首先删除文件冗余,在可能的情况下最大限度地提高缓存命中率并节省用户成本。
我们最终设计这个框架是为了可扩展,允许未来的上下文管理改进,同时与检查点等其他功能顺利集成。
其他上下文相关事项
我们还在迭代其他方法来减少 token 使用,包括更改我们的系统提示词。Cline 在 AI 编码代理中为如何构建和使用 MCP 服务器树立了标准。但以前一些与使用 MCP 服务器相关的指令夸大了我们系统提示词的长度。到目前为止,我们使用了 30% 的系统提示词来指导 Cline 如何构建和使用 MCP 服务器。
这组静态指令正在被一个 load_mcp_documentation 工具取代。这使得 Cline 仅在 MCP 相关任务明确需要时才检索大约 8,000 个 token 的文档,从而消除了按请求产生的开销。
我对此感到兴奋的事情
我们已经确定了其他类似的方法来改进我们对上下文窗口的管理,但为什么止步于此呢?如果 Cline 同时选择上下文中最重要的消息来维护呢?如果 Cline 以一种最大限度地提高效率并使用完成用户任务所需的最少 token 数量的方式来总结与用户的对话历史呢?等等等等,我们有很多正在努力的事情 :)
我们致力于继续最大限度地提高效率和性能,更棒的是,这不是一种权衡:效率、可负担性和性能都是一致的。我对接下来会发生的事情感到兴奋。
感谢各位朋友支持 Cline。
-Toshi


