
将差异编辑改进 10%
在修改代码方面,Cline 的工具包中有两种主要方法:
1. write_to_file 用于创建或覆盖整个文件,以及
2. replace_in_file 用于进行精细的、有针对性的更改(差异编辑)。
我们将这些有针对性的更改称为“差异编辑”,它们的可靠性是代理性能的基础。作为我们优化代理每个核心子系统工作的一部分,我们一直专注于提高这些差异编辑的成功率。
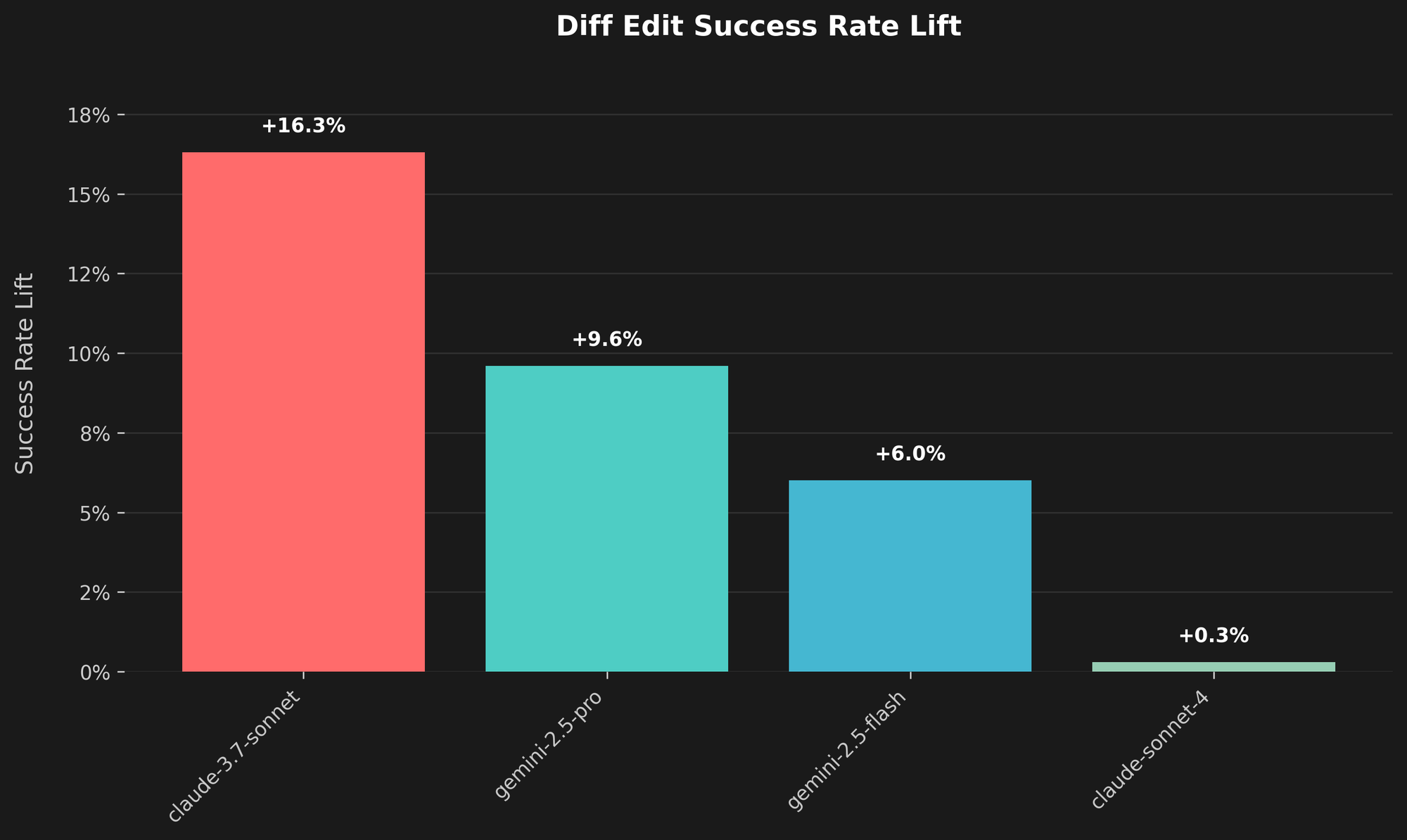
结果如何?我们最近发布了一种新的差异应用算法和针对特定模型的提示词更改,这使得所有模型的 diffEditSuccess 率平均提高了 10% 以上。
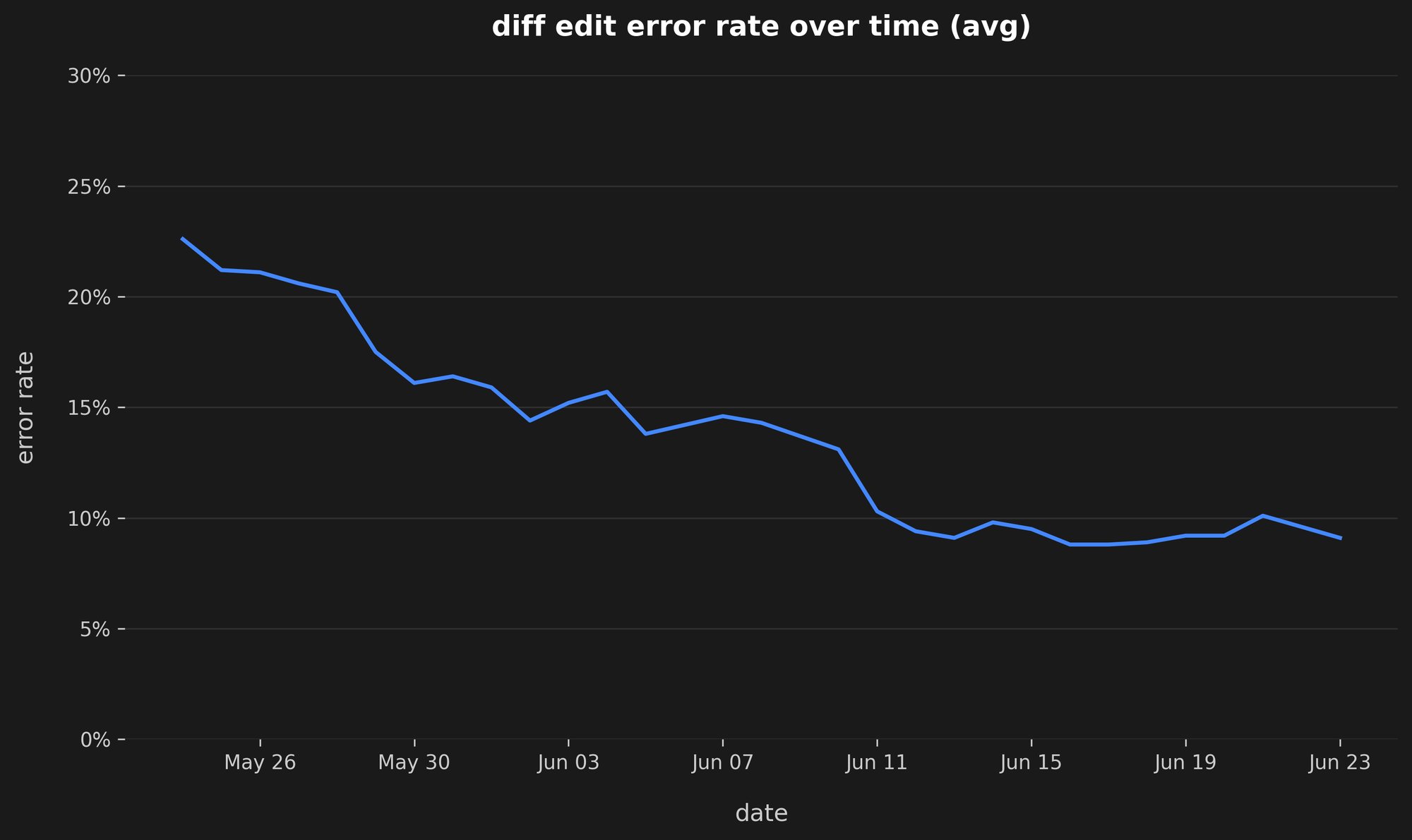
为了实现这一目标,我们构建了一个开源评估系统,用于严格测试差异编辑管道的每个组件。该系统允许我们系统地更改每个组件——包括系统提示词、解析逻辑以及差异应用算法本身——并根据我们在内部收集的一套真实用户场景进行测试。
我们的评估框架迅速发现了一个常见且令人沮丧的失败案例:许多大型语言模型(LLM)尽管被明确提示要按正确顺序生成差异,但经常会返回乱序的差异。这是一个不遵循指令的根本问题。
我们的解决方案是双管齐下的。首先,我们开发了一种新的、“顺序无关的多差异应用”算法。简单来说,即使模型以错误的顺序提供搜索和替换块系列,它也能正确应用它们。其次,我们增加了对多种差异格式的支持,以解决特定模型的怪癖。例如,Anthropic 的模型针对 ---/+++ 标记进行了优化,而 Gemini 和 xAI 模型在使用 >>>/<<< 块时表现更好。我们的系统现在可以同时处理这两种格式,确保无论用户选择哪个模型,都能获得更高的可靠性。这些更改共同对可靠性产生了重大影响。
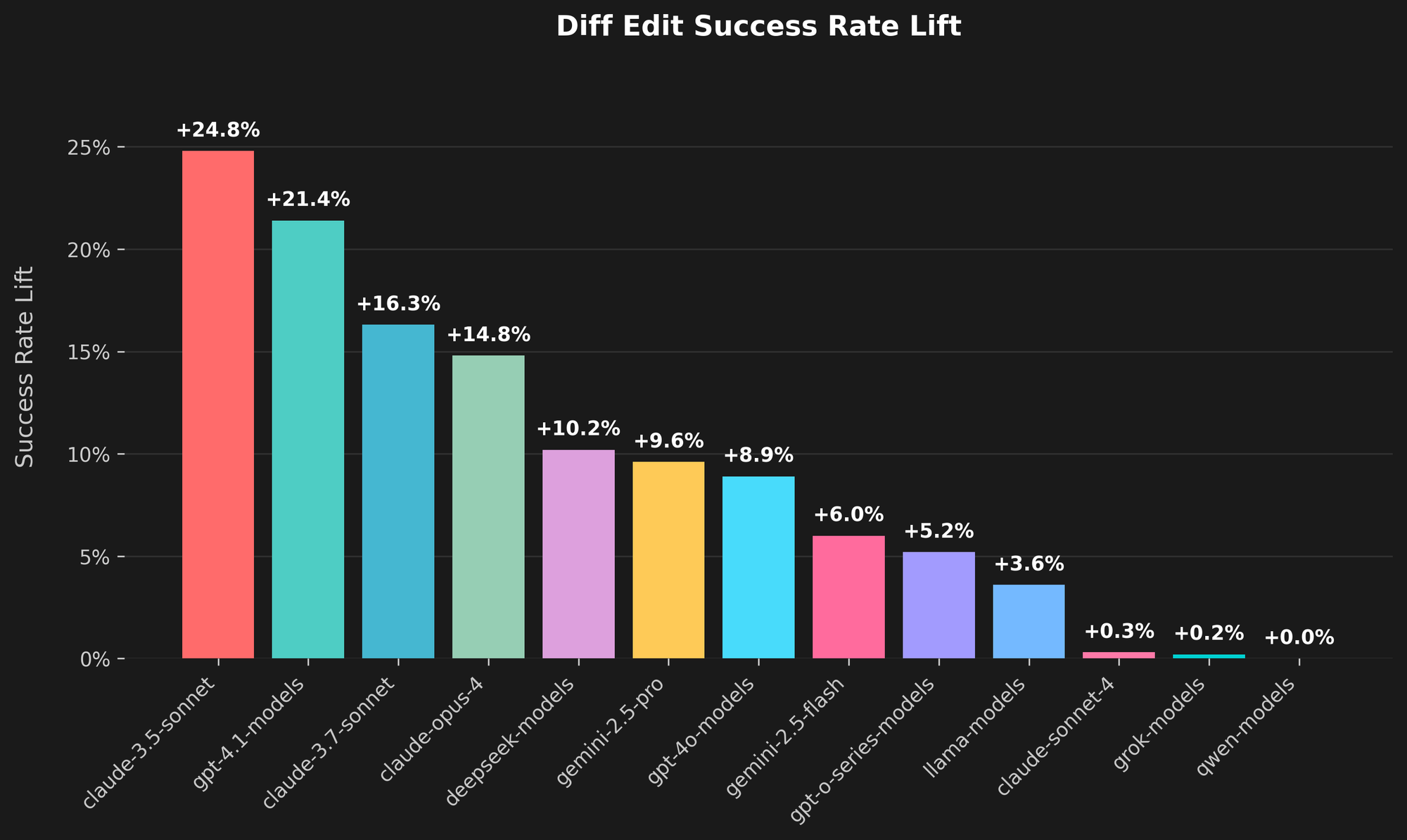
数据显示,整体上有了明显的提升。对于将 Cline 连接到 Claude 3.5 Sonnet 的用户,差异编辑的成功率提高了近 25%。其他模型也显示出显著的提升,GPT-4.1 模型提高了 21% 以上,Claude Opus 4 提高了近 15%。
这就是在代理范式下构建的样子——这是一个持续的测量、分析和有针对性改进的过程。通过构建评估我们自己系统的工具,我们可以超越轶事证据,做出数据驱动的决策,从而为每个人带来更强大、更可靠的代理。
我们的目标是 0% 的错误率,这是朝着这个方向迈出的重要一步。
如果您对技术细节感兴趣或想将我们的评估框架用于您自己的项目,您可以在我们的 GitHub 上找到整个开源系统这里。
像这样的工作每天都在 Cline 进行。如果您热衷于构建软件开发的未来并希望解决此类问题,请查看我们这里的空缺职位。