
构建智能体中的 3 个诱人陷阱
在 Cline 构建 AI 智能体的过程中,我们发现最危险的想法不是那些明显糟糕的想法,而是那些听起来很棒但在实践中失败的诱人想法。这些“思维病毒”已经感染了整个行业,造成了数百万美元的工程时间浪费,并导致团队陷入架构死胡同。
以下是我们看到团队最常陷入的三个陷阱
- 多智能体编排
- 通过索引代码库进行 RAG(检索增强生成)
- 更多指令 = 更好的结果
让我们来探讨一下原因!
(1) 多智能体编排
科幻小说中描绘的智能体(“后方智能体、季度智能体、分析器智能体、编排器智能体”)发出大量子智能体并组合其结果的愿景听起来很吸引人,但在现实中,大多数有用的智能体工作都是单线程的。
目前多智能体系统取得的最大进展来自 Anthropic,但即使他们也承认构建和对齐多个智能体极其困难。正如他们的团队所说
"智能体系统中错误的复合性质意味着传统软件中的小问题可能会完全破坏智能体。一个步骤失败可能导致智能体探索完全不同的轨迹,从而导致不可预测的结果。出于本文所述的所有原因,原型和生产之间的差距通常比预期的要大。"
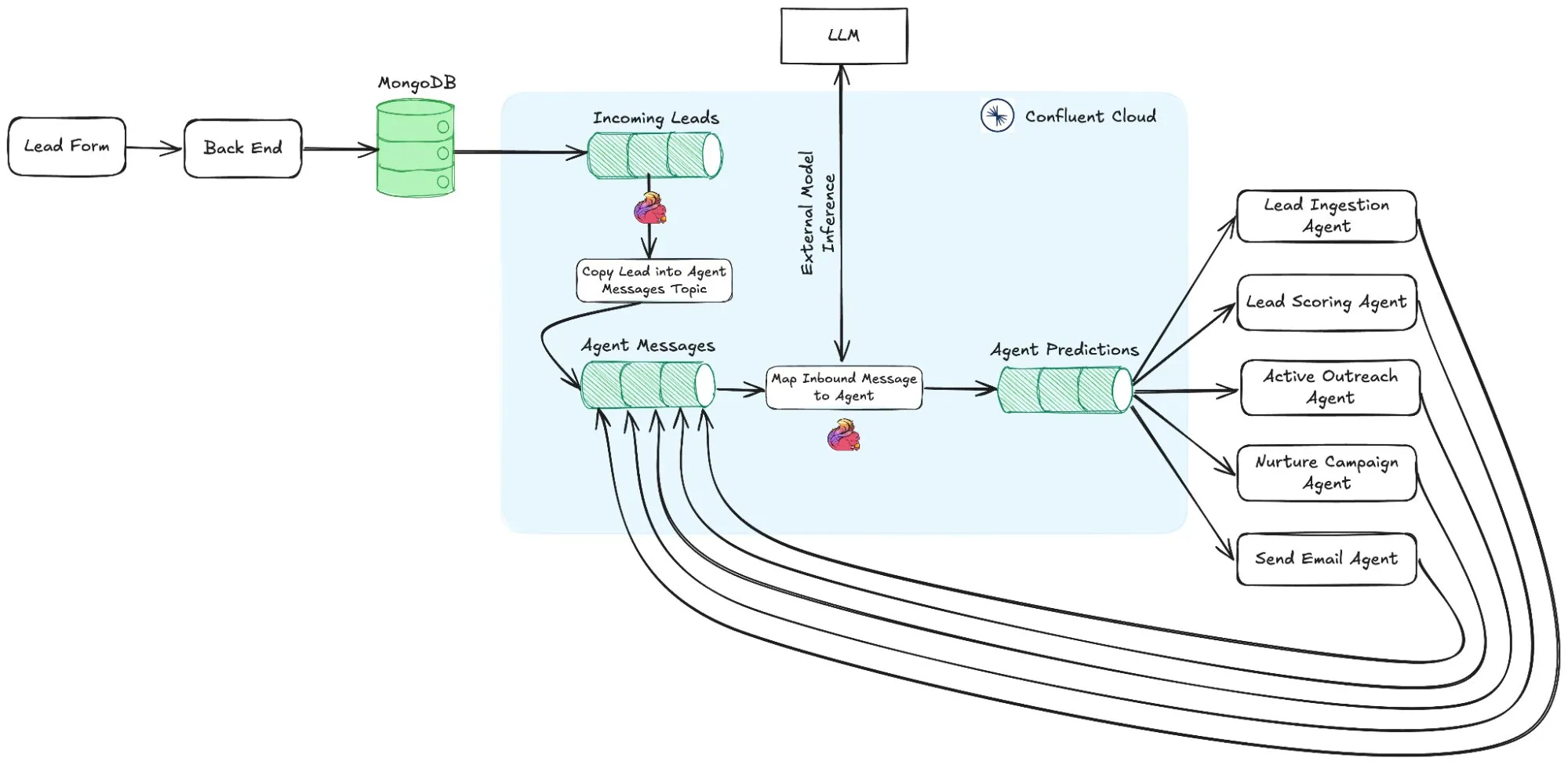
这并不是说我们完全反对多智能体,对于小的特定用例来说,拥有具有有限工具功能的子智能体是完全可行的。
例如,在主智能体线程生成几个子智能体并行读取文件的情况下。或者,您可以使用子智能体执行琐碎的任务,例如从网络获取数据。但这大多与进行并行工具调用本质上相同,所以我甚至不确定它是否符合“真正的”多智能体编排。
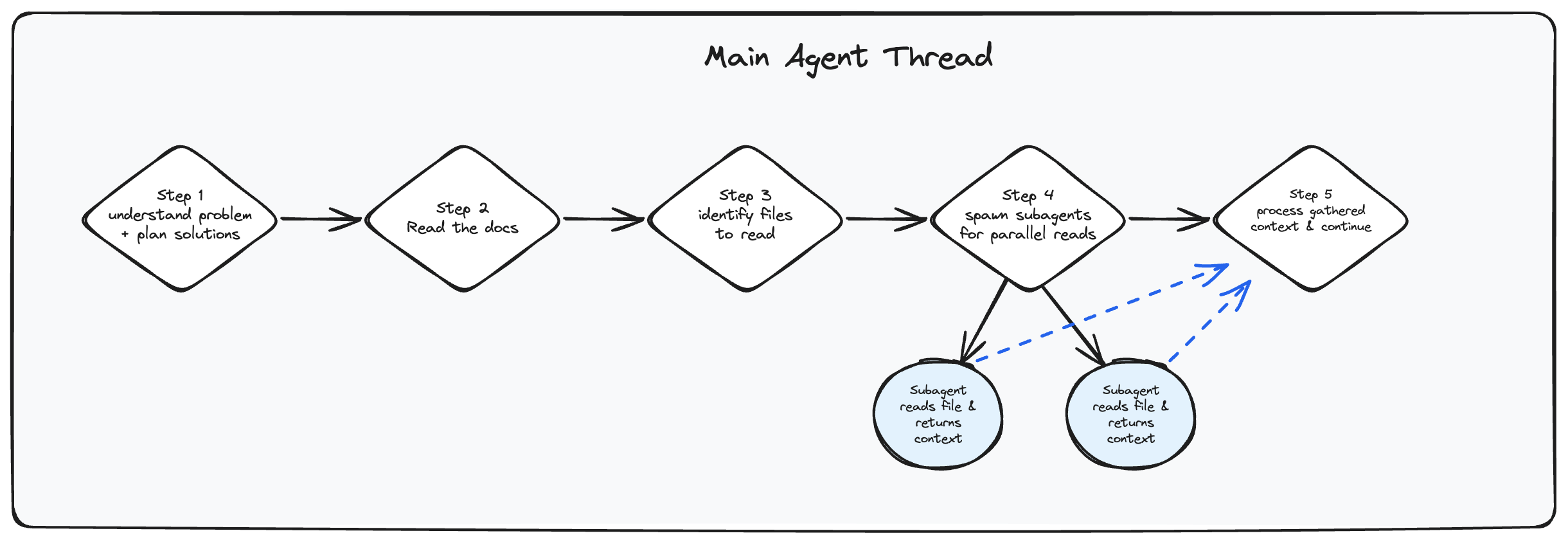
(2) RAG(检索增强生成)
RAG 是另一个从较小上下文窗口时代遗留下来的诱人陷阱,当时赋予智能体查询“整个代码库”的能力感觉很诱人。但 RAG 的炒作并未转化为实用的编码智能体工作流程,因为它通常会产生分散的代码,而没有为模型提供任何真正的“上下文理解”。它在纸面上看起来很强大,但在实践中,即使是像 GREP 这样简单的东西也能更好地发挥作用,特别是对于智能体而言。
让智能体像人一样列出文件、使用 grep 搜索文件,然后打开并阅读整个文件几乎总是更好的选择。Cline 从一开始就树立了这种方法的标准,此后它定义了元数据,Amp Code 和 Cursor 也纷纷效仿。
大多数公司一开始都使用向量数据库,因为当“与代码聊天”的 VS Code 扩展于 2023 年首次出现时,模型只有 8,092 个 token 的上下文窗口,因此挤入模型的每一行都必须精心制作。当时这很有意义,这就是为什么如此多的基础设施和炒作投入到向量数据库公司,有些公司筹集了数亿美元,比如 Pinecone。Cline 于 2024 年 7 月推出,当时领先的编码模型是 Claude 3.5 Sonnet,具有 200K token 的上下文窗口,因此它从未受到需要拼接不相关上下文片段的限制。
(3) 更多指令 = 更好的结果
通过在系统提示中堆叠越来越多的“指令”使模型更智能的神话是完全错误的。提示过载只会使模型感到困惑,因为额外的指令通常会相互冲突并产生噪音。你最终会玩打地鼠式的行为,而不是得到有用的输出。对于当今大多数前沿模型来说,最好是退后一步,让它们工作,而不是通过提示不断地对它们大喊大叫。仔细衡量你的措辞。
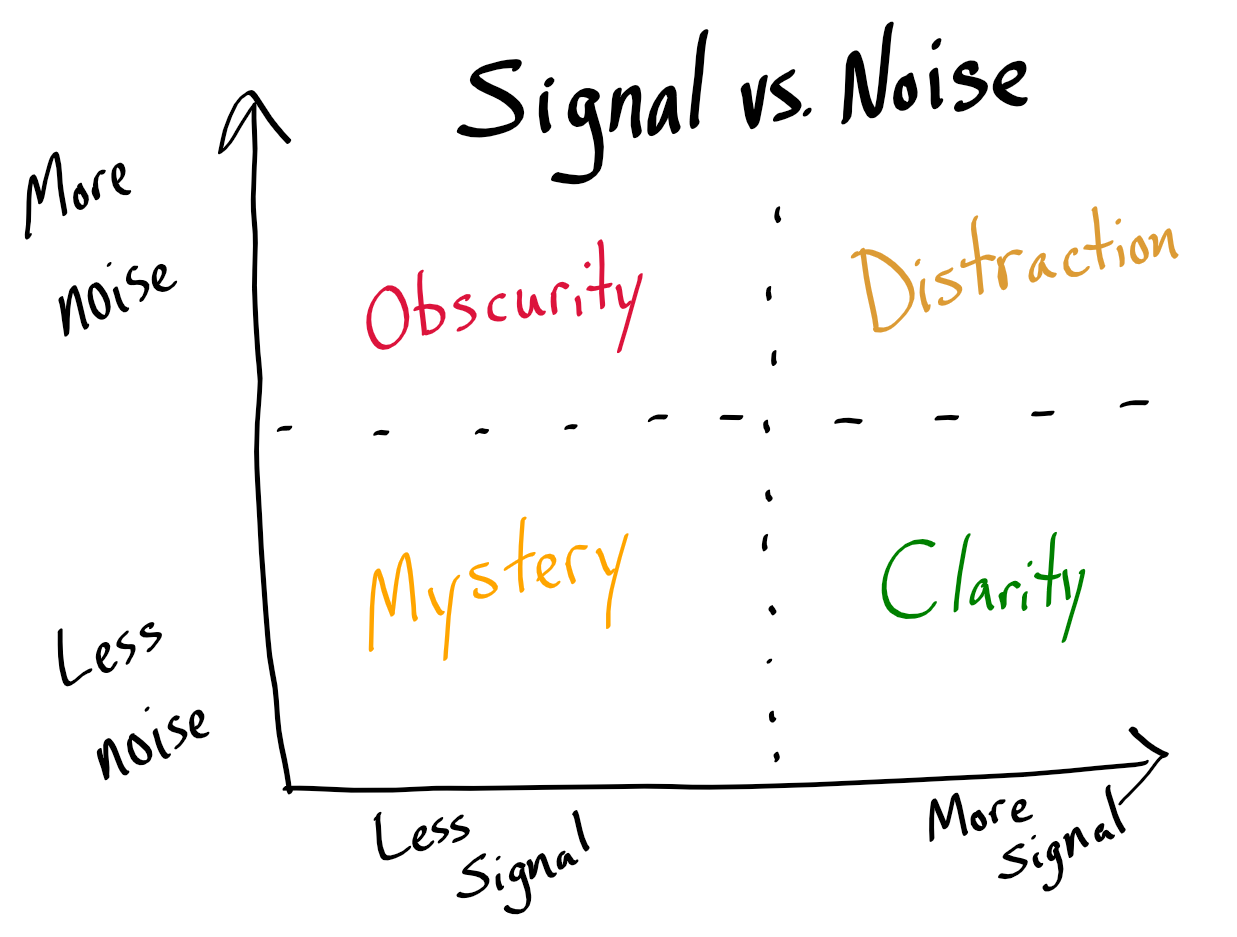
当 Cline 在 2024 年年中推出时,Sonnet 3.5 是领先的模型,当时用示例和想法来填充提示是合理的。但是当 Sonnet 4 系列到来时,这种方法完全失败了,所有其他智能体系统也随之失败了。通过迭代,我们意识到核心问题:过多的指令会产生矛盾,而矛盾会产生混乱。
新的前沿模型,Claude 4、Gemini 2.5 和 GPT-5,更擅长遵循简洁的指示。它们不需要长篇大论,它们只需要最低限度的要求。这就是新的现实。
多智能体编排、RAG 和过度填充的提示在纸面上看起来很吸引人,但没有一个能在实际开发工作流程中经受住考验。获胜的智能体是那些拥抱简单性的智能体:像开发人员一样阅读代码,相信模型的能力,然后让开。
虽然业界仍在追逐架构复杂性,但基本面已经转变。少即是多,清晰胜过巧妙,最好的 AI 智能体往往是最简单的一个。
-Ara